0 问题描述
人脸检测,即检测图片上人脸位置。传统的方法是首先生成候选窗,然后将候选窗输入到CNN网络进行检测。本文中生成候选窗的过程使用CNN网络的卷积过程完成。基于CNN网络端到端的特性,使用三级网络。第一级产生候选窗,第二级网络改善候选窗,第三级网络确定最终的人脸框和五个特征点位置。
1 本文贡献点
(1)提出一种新的级联结构,设计轻量结构的CNN以完成实时处理 (2)提出一种effective method 利用网络 hard sample mining 提高 performance. (3)使用实验结果与state-of-the-art techniques对比in both face detection and face alignment tasks。
2 Ovrall Framework
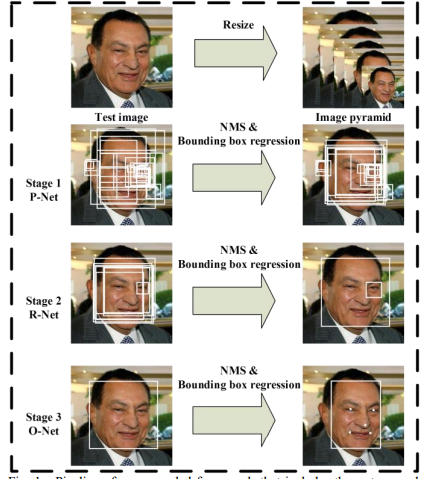
Fig. 1. Pipeline of our cascaded framework that includes three-stage multi-task deep convolutional networks. Firstly, candidate windows are produced through a fast Proposal Network (P-Net). After that, we refine these candidates in the next stage through a Refinement Network (R-Net). In the third stage, The Output Network (O-Net) produces final bounding box and facial landmarks position
给出一副image,把image resize 不同的大小,形成image pyramid(图像金字塔),作为下面网络的输入。
Stage 1:提出一种a fully convolutional network,Proposal Network(P-neteork)。主要产生候选窗口,以及(calibration) box regression vectors(参照上篇论文,基于45个变换得到组合box 向量)。然后使用NMS方法去掉相似度高的box。
stage 2:所有候选窗口被输入到Refine Network(R-Net),可以rejects 更多的候选窗口,performs calibration with bounding box regression and NMS candidata merge.
stage 3:类似于第二步,但是这一步针对更多细节,即完成alignment.
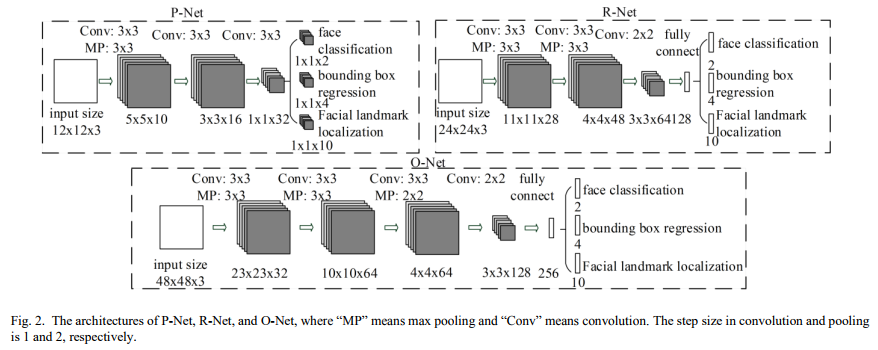
3 CNN Architectures
上文CNN的问题
(1) Some filters lack diversity of weights that may limit them to produce discriminative description.
(2) Compared to other multi-class objection detection and classification tasks, face detection is a challenge binary classification task, so it may need less numbers of filters but more discrimination of them。
改进:
(1)we reduce the number of filters and change the 5×5 filter to a 3×3 filter to reduce the computing while increase the depth to get better performance.
4 training
1) Face classification: The learning objective is formulated as a two-class classification problem. For each sample , we use the cross-entropy loss:

2) Bounding box regression: For each candidate window, we predict the offset between it and the nearest ground truth (i.e., the bounding boxes’ left top, height, and width).Euclidean loss:

3) Facial landmark localization: Similar to the bounding box regression task, facial landmark detection is formulated as a regression problem and we minimize the Euclidean loss:

4) Multi-source training: Since we employ different tasks in each CNNs, there are different types of training images in the learning process, such as face, non-face and partially aligned face.such as face, non-face and partially aligned face. In this case, some of the loss functions (i.e., Eq. (1)-(3) ) are not used. For example, for the sample of background region, we only compute , and the other two losses are set as 0. This can be implemented directly with a sample type indicator. Then the overall learning target can be formulated as:

5) Online Hard sample mining: Different from conducting traditional hard sample mining after original classifier had been trained, we do online hard sample mining in face classification task to be adaptive to the training process。
In particular, in each mini-batch, we sort the loss computed in the forward propagation phase from all samples and select the top 70% of them as hard samples. Then we only compute the gradient from the hard samples in the backward propagation phase. That means we ignore the easy samples that are less helpful to strengthen the detector while training. Experiments show that this strategy yields better performance without manual sample selection.
传统的难例处理方法是检测过一次以后,手动检测哪些困难的样本无法被分类,本文采用online hard sample mining的方法。具体就是在每个mini-batch中,取loss最大的70%进行反向传播,忽略那些简单的样本。
5 实验
本文主要使用三个数据集进行训练:FDDB,Wider Face,AFLW。
A、训练数据
本文将数据分成4种:
Negative:非人脸
Positive:人脸
Part faces:部分人脸
Landmark face:标记好特征点的人脸
分别用于训练三种不同的任务。Negative和Positive用于人脸分类,positive和part faces用于bounding box regression,landmark face用于特征点定位。
B、效果
本文的人脸检测和人脸特征点定位的效果都非常好。关键是这个算法速度很快,在2.6GHZ的CPU上达到16fps,在Nvidia Titan达到99fps。